Core Concepts
Given Llama Stack’s service-oriented philosophy, a few concepts and workflows arise which may not feel completely natural in the LLM landscape, especially if you are coming with a background in other frameworks.
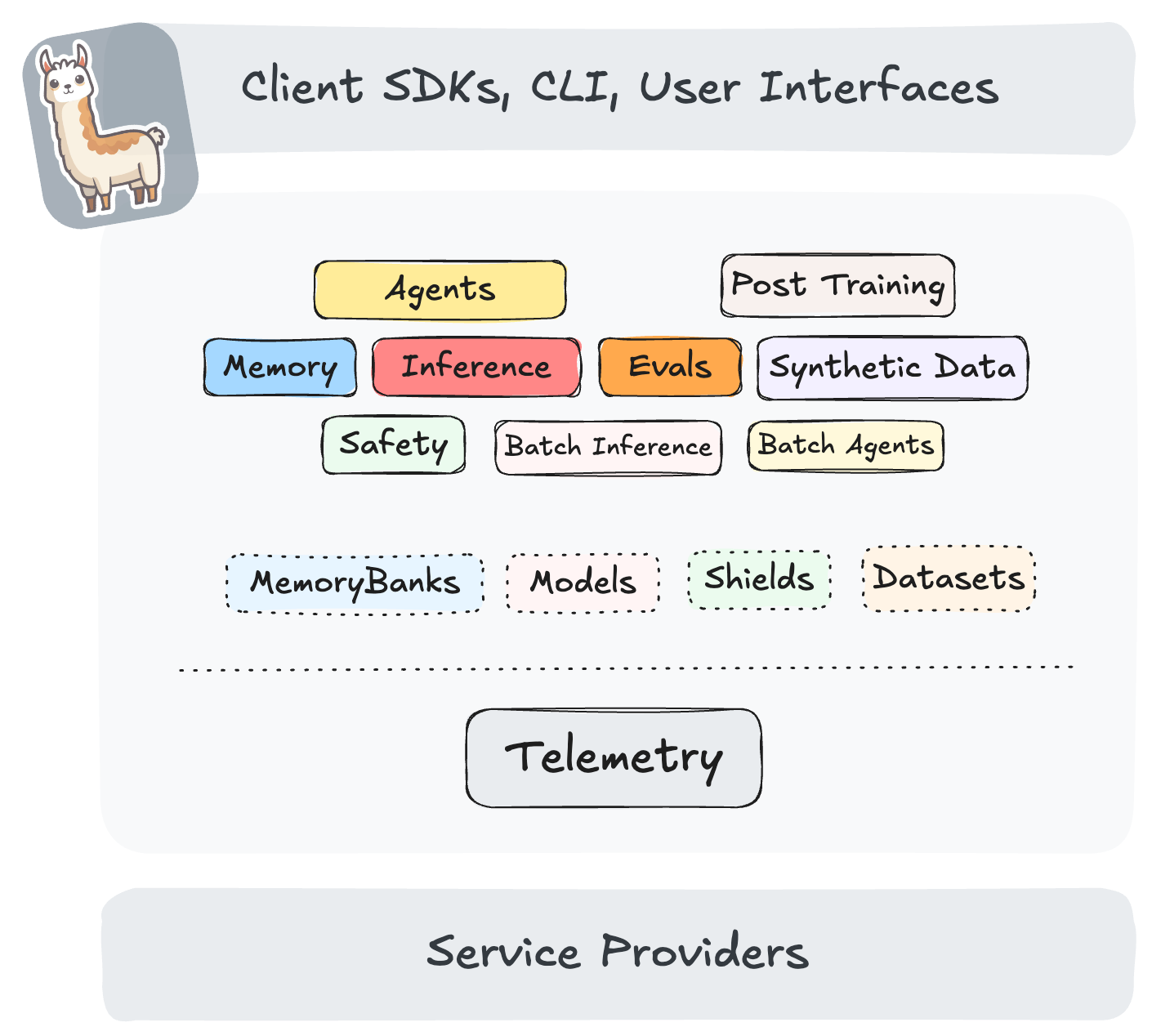
Llama Stack architecture
Llama Stack allows you to build different layers of distributions for your AI workloads using various SDKs and API providers.
Benefits of Llama stack
Current challenges in custom AI applications
Building production AI applications today requires solving multiple challenges:
Infrastructure Complexity
Running large language models efficiently requires specialized infrastructure.
Different deployment scenarios (local development, cloud, edge) need different solutions.
Moving from development to production often requires significant rework.
Essential Capabilities
Safety guardrails and content filtering are necessary in an enterprise setting.
Just model inference is not enough - Knowledge retrieval and RAG capabilities are required.
Nearly any application needs composable multi-step workflows.
Without monitoring, observability and evaluation, you end up operating in the dark.
Lack of Flexibility and Choice
Directly integrating with multiple providers creates tight coupling.
Different providers have different APIs and abstractions.
Changing providers requires significant code changes.
Our Solution: A Universal Stack
Llama Stack addresses these challenges through a service-oriented, API-first approach:
Develop Anywhere, Deploy Everywhere
Start locally with CPU-only setups
Move to GPU acceleration when needed
Deploy to cloud or edge without code changes
Same APIs and developer experience everywhere
Production-Ready Building Blocks
Pre-built safety guardrails and content filtering
Built-in RAG and agent capabilities
Comprehensive evaluation toolkit
Full observability and monitoring
True Provider Independence
Swap providers without application changes
Mix and match best-in-class implementations
Federation and fallback support
No vendor lock-in
Robust Ecosystem
Llama Stack is already integrated with distribution partners (cloud providers, hardware vendors, and AI-focused companies).
Ecosystem offers tailored infrastructure, software, and services for deploying a variety of models.
Our Philosophy
Service-Oriented: REST APIs enforce clean interfaces and enable seamless transitions across different environments.
Composability: Every component is independent but works together seamlessly
Production Ready: Built for real-world applications, not just demos
Turnkey Solutions: Easy to deploy built in solutions for popular deployment scenarios
With Llama Stack, you can focus on building your application while we handle the infrastructure complexity, essential capabilities, and provider integrations.
APIs
A Llama Stack API is described as a collection of REST endpoints. We currently support the following APIs:
Inference: run inference with a LLM
Safety: apply safety policies to the output at a Systems (not only model) level
Agents: run multi-step agentic workflows with LLMs with tool usage, memory (RAG), etc.
DatasetIO: interface with datasets and data loaders
Scoring: evaluate outputs of the system
Eval: generate outputs (via Inference or Agents) and perform scoring
VectorIO: perform operations on vector stores, such as adding documents, searching, and deleting documents
Telemetry: collect telemetry data from the system
Post Training: fine-tune a model
Tool Runtime: interact with various tools and protocols
Responses: generate responses from an LLM using this OpenAI compatible API.
We are working on adding a few more APIs to complete the application lifecycle. These will include:
Batch Inference: run inference on a dataset of inputs
Batch Agents: run agents on a dataset of inputs
Synthetic Data Generation: generate synthetic data for model development
Batches: OpenAI-compatible batch management for inference
API Providers
The goal of Llama Stack is to build an ecosystem where users can easily swap out different implementations for the same API. Examples for these include:
LLM inference providers (e.g., Fireworks, Together, AWS Bedrock, Groq, Cerebras, SambaNova, vLLM, etc.),
Vector databases (e.g., ChromaDB, Weaviate, Qdrant, Milvus, FAISS, PGVector, etc.),
Safety providers (e.g., Meta’s Llama Guard, AWS Bedrock Guardrails, etc.)
Providers come in two flavors:
Remote: the provider runs as a separate service external to the Llama Stack codebase. Llama Stack contains a small amount of adapter code.
Inline: the provider is fully specified and implemented within the Llama Stack codebase. It may be a simple wrapper around an existing library, or a full fledged implementation within Llama Stack.
Most importantly, Llama Stack always strives to provide at least one fully inline provider for each API so you can iterate on a fully featured environment locally.
Distributions
While there is a lot of flexibility to mix-and-match providers, often users will work with a specific set of providers (hardware support, contractual obligations, etc.) We therefore need to provide a convenient shorthand for such collections. We call this shorthand a Llama Stack Distribution or a Distro. One can think of it as specific pre-packaged versions of the Llama Stack. Here are some examples:
Remotely Hosted Distro: These are the simplest to consume from a user perspective. You can simply obtain the API key for these providers, point to a URL and have all Llama Stack APIs working out of the box. Currently, Fireworks and Together provide such easy-to-consume Llama Stack distributions.
Locally Hosted Distro: You may want to run Llama Stack on your own hardware. Typically though, you still need to use Inference via an external service. You can use providers like HuggingFace TGI, Fireworks, Together, etc. for this purpose. Or you may have access to GPUs and can run a vLLM or NVIDIA NIM instance. If you “just” have a regular desktop machine, you can use Ollama for inference. To provide convenient quick access to these options, we provide a number of such pre-configured locally-hosted Distros.
On-device Distro: To run Llama Stack directly on an edge device (mobile phone or a tablet), we provide Distros for iOS and Android
Resources
Some of these APIs are associated with a set of Resources. Here is the mapping of APIs to resources:
Inference, Eval and Post Training are associated with
Modelresources.Safety is associated with
Shieldresources.Tool Runtime is associated with
ToolGroupresources.DatasetIO is associated with
Datasetresources.VectorIO is associated with
VectorDBresources.Scoring is associated with
ScoringFunctionresources.Eval is associated with
ModelandBenchmarkresources.
Furthermore, we allow these resources to be federated across multiple providers. For example, you may have some Llama models served by Fireworks while others are served by AWS Bedrock. Regardless, they will all work seamlessly with the same uniform Inference API provided by Llama Stack.
Registering Resources
Given this architecture, it is necessary for the Stack to know which provider to use for a given resource. This means you need to explicitly register resources (including models) before you can use them with the associated APIs.